基于大數(shù)據(jù)的輿情分析系統(tǒng)架構 數(shù)據(jù)處理與存儲支持服務詳解
隨著社交媒體和數(shù)字信息的爆炸式增長,對網絡輿情的實時、精準分析變得至關重要。一套高效的基于大數(shù)據(jù)的輿情分析系統(tǒng),其核心能力很大程度上依賴于健壯的數(shù)據(jù)處理與存儲支持服務。本文將深入探討該架構中數(shù)據(jù)處理與存儲層的設計理念、關鍵組件與技術選型。
一、 總體架構定位
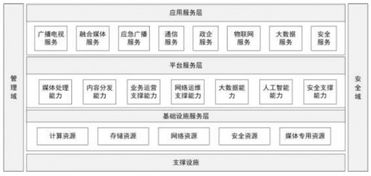
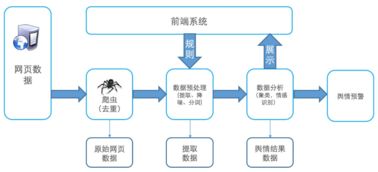
在輿情分析系統(tǒng)的分層架構中,數(shù)據(jù)處理與存儲支持服務位于數(shù)據(jù)層,是連接底層數(shù)據(jù)采集與上層分析應用的橋梁。其主要職責是承接海量、多源、異構的原始輿情數(shù)據(jù)(如新聞、微博、論壇帖子、評論、視頻彈幕等),經過一系列處理,轉化為清潔、規(guī)整、易于分析的高價值數(shù)據(jù)資產,并提供高效、可靠的存儲與訪問服務。
二、 數(shù)據(jù)處理流程與關鍵技術
數(shù)據(jù)處理流程通常遵循“采集-清洗-集成-轉換-加載”的管道模式,并引入實時流處理以滿足時效性要求。
- 多源數(shù)據(jù)采集與接入:
- 技術組件:使用如Flume、Logstash、Sqoop等工具,以及自研的API爬蟲框架,從網站、API接口、移動應用、數(shù)據(jù)庫等多種信源實時或批量采集數(shù)據(jù)。
- 挑戰(zhàn)與策略:應對反爬機制、處理不同數(shù)據(jù)格式(JSON、XML、HTML、純文本)、保證數(shù)據(jù)的完整性與連續(xù)性。
- 實時流處理:
- 技術選型:Apache Kafka作為高吞吐量的分布式消息隊列,是流數(shù)據(jù)的“中樞神經”。后續(xù)使用Apache Flink或Apache Storm進行實時計算,實現(xiàn)數(shù)據(jù)的即時清洗、初步篩選(如關鍵詞過濾)、情感傾向性基礎判斷。
- 價值:對突發(fā)事件、熱點話題實現(xiàn)分鐘級甚至秒級的感知與響應。
- 批處理與數(shù)據(jù)清洗:
- 技術選型:Apache Spark或Hadoop MapReduce用于處理海量歷史數(shù)據(jù)及復雜的清洗轉換任務。
- 核心任務:
- 去重與去噪:消除重復轉載、垃圾廣告、無關信息。
- 結構化提取:從非結構化文本中抽取實體(人名、機構名、地名、產品名)、關鍵詞、主題。
- 標準化:統(tǒng)一編碼、時間格式、單位等。
- 情感標注:結合詞典與機器學習模型,為文本打上情感標簽。
- 數(shù)據(jù)集成與轉換:
- 將清洗后的數(shù)據(jù)與內部業(yè)務數(shù)據(jù)(如客戶信息、產品目錄)進行關聯(lián)。
- 將數(shù)據(jù)轉換為適合后續(xù)分析與挖掘的模型,例如構建“事件-觀點-情感”關系圖譜的底層數(shù)據(jù)表。
三、 數(shù)據(jù)存儲架構設計
輿情數(shù)據(jù)的多模態(tài)(文本、圖片、視頻鏈接、結構化元數(shù)據(jù))和訪問模式多樣性(實時查詢、批量分析、模型訓練)要求采用混合存儲策略。
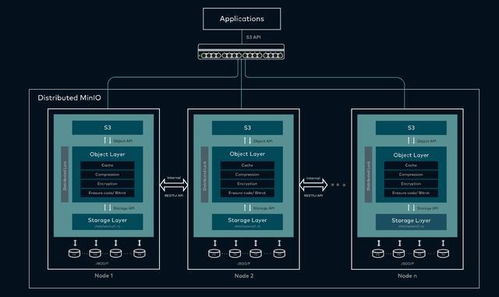
- 分布式文件系統(tǒng):
- 角色:存儲最原始的、未經處理的或經過簡單分區(qū)的海量數(shù)據(jù),作為數(shù)據(jù)湖的基底。
- 技術選型:Hadoop HDFS或云對象存儲(如AWS S3,阿里云OSS)。特點是成本低、容量無限擴展、適合順序訪問。
- NoSQL數(shù)據(jù)庫:
- 角色:存儲清洗后、需要支持高并發(fā)實時查詢和靈活模式的數(shù)據(jù)。
- 技術選型:
- 寬列存儲:如Apache HBase、Cassandra。適用于存儲輿情事件詳情、用戶畫像信息,支持按行鍵快速查詢。
- 文檔數(shù)據(jù)庫:如MongoDB、Elasticsearch。Elasticsearch憑借其強大的全文檢索和近實時搜索能力,常作為處理后的輿情文本的核心存儲與索引引擎,支持復雜聚合分析。
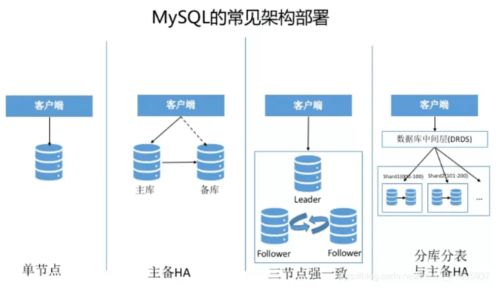
- 關系型數(shù)據(jù)庫與數(shù)據(jù)倉庫:
- 角色:存儲高度結構化、用于BI報表、趨勢分析和模型訓練的特征數(shù)據(jù)、結果數(shù)據(jù)。
- 技術選型:MySQL/PostgreSQL用于存儲元數(shù)據(jù)和管理信息;云數(shù)據(jù)倉庫(如Snowflake、阿里云MaxCompute)或基于Hive的離線數(shù)倉用于承載大規(guī)模分析任務。
- 緩存層:
- 角色:加速熱點數(shù)據(jù)(如正在爆發(fā)的熱點事件詳情、實時統(tǒng)計儀表盤數(shù)據(jù))的訪問。
- 技術選型:Redis或Memcached。
四、 支持服務與數(shù)據(jù)治理
- 元數(shù)據(jù)管理:記錄數(shù)據(jù)的來源、格式、含義、處理歷史、血緣關系,確保數(shù)據(jù)的可追溯性與可信度。
- 數(shù)據(jù)質量監(jiān)控:設立數(shù)據(jù)質量檢查點,監(jiān)控數(shù)據(jù)采集的完整性、清洗的有效性、存儲的可用性。
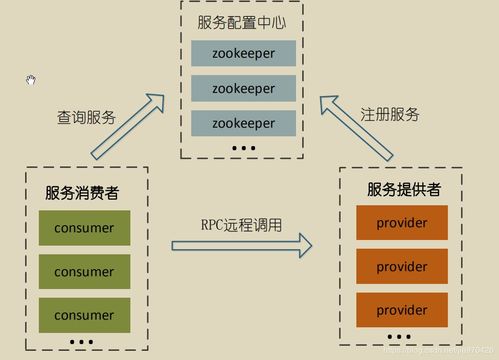
- 資源調度與協(xié)調:使用YARN或Kubernetes管理計算資源,使用ZooKeeper協(xié)調分布式組件狀態(tài)。
- 安全與權限:實施數(shù)據(jù)加密(傳輸中/靜止時)、訪問控制、脫敏處理,確保合規(guī)性。
五、
一個成功的輿情分析系統(tǒng),其數(shù)據(jù)處理與存儲支持服務必須兼具高吞吐、低延遲、高可靠、易擴展的特性。通過融合流批一體的處理框架(如Flink)、分層分域的混合存儲方案,并輔以完善的數(shù)據(jù)治理工具,才能將洶涌而來的數(shù)據(jù)洪流,轉化為驅動輿情洞察、輔助決策制定的清澈“信息活水”。這套架構不僅支撐了實時預警、情感分析、趨勢預測等核心應用,也為更高級別的NLP模型訓練和人工智能應用奠定了堅實的數(shù)據(jù)基石。
如若轉載,請注明出處:http://m.nrt6.cn/product/63.html
更新時間:2026-04-14 00:20:33